
DP-Siam Tracker
DP-Siam: Dynamic Policy Siamese Network for Robust Object Tracking
Balancing the trade-off between real-time performance and accuracy in object tracking is a major challenging problem. In this paper, a novel dynamic policy gradient Agent-Environment architecture with Siamese network (DP-Siam) is proposed to train the tracker to increase the accuracy and the expected average overlap while performing in real-time. DP-Siam is trained offline with reinforcement learning to produce a continuous action that predicts the optimal object's location. DP-Siam has a novel architecture that consists of three networks: an Agent network to predict the optimal state (bounding box) of the object being tracked, and an Environment network to get the Q-value during the offline training phase to minimize the error of the loss function, and a Siamese network to produce a heat-map. During the online tracking, the Environment network acts as a verifier to the Agent network action. Extensive experiments are performed on six widely used benchmarks: OTB2013, OTB50, OTB100, VOT2015, VOT2016 and VOT2018. The results show that DP-Siam significantly outperforms the current state-of-the-art trackers.
Download the pretrained networks
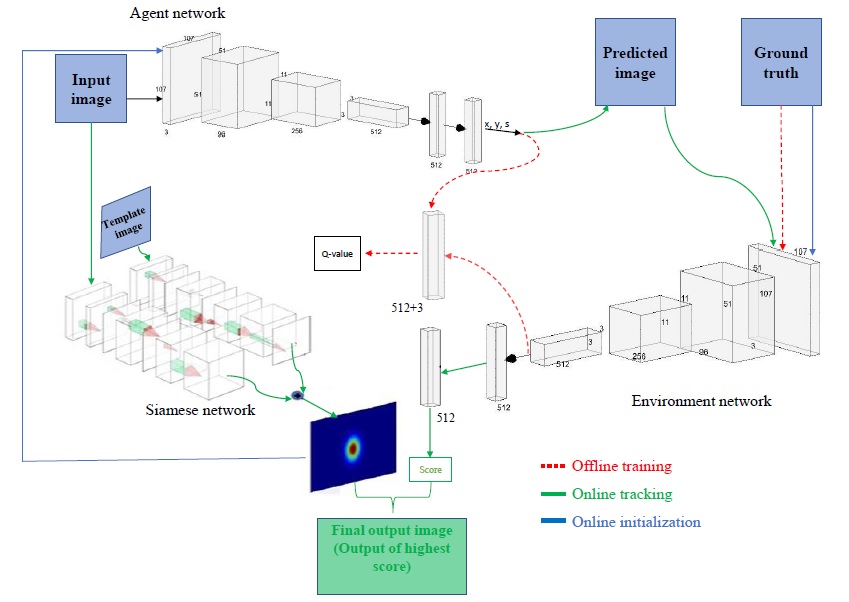
DP-Siam Architecture
In this section we show the architecture of DP-Siam. Data dimensions are shown in Table I.
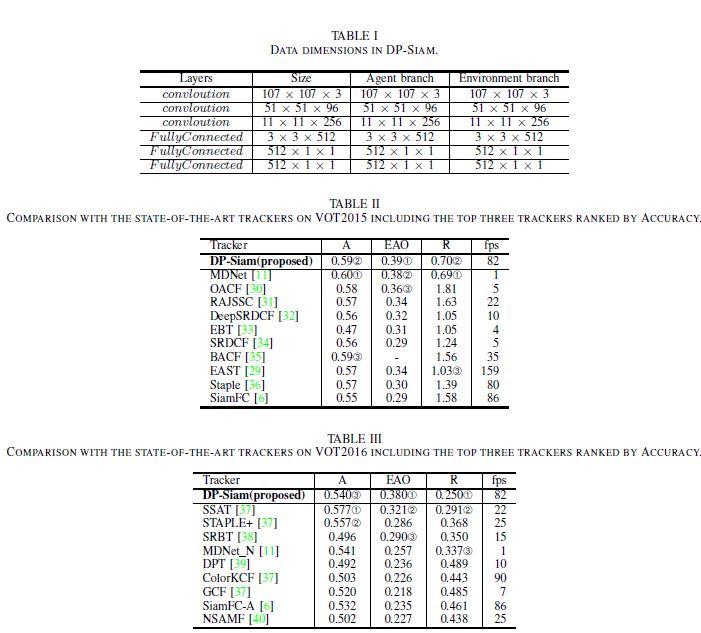
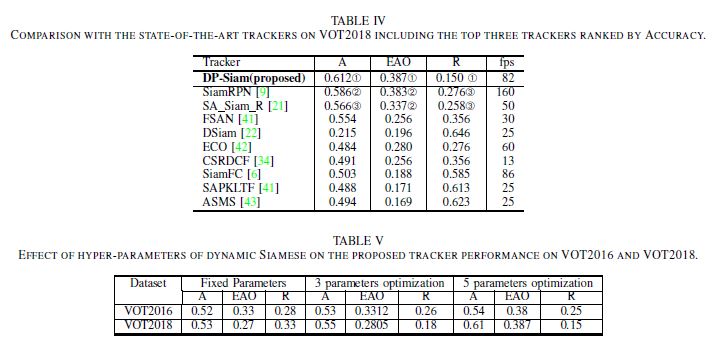
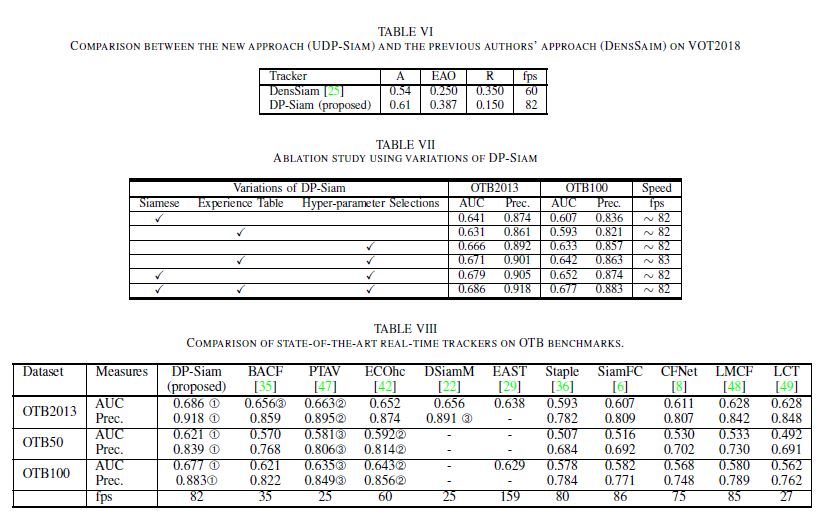
Experiments
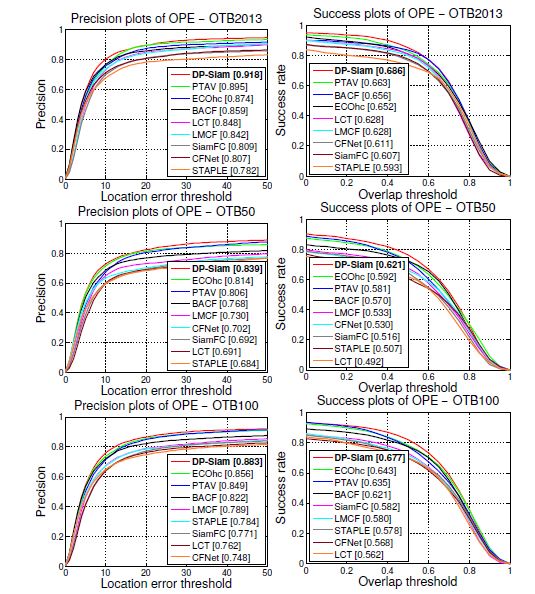
We evaluated DP-Siam on OTB2013, OTB50, OTB100, VOT2015, VOT2016, and VOT2018.
samples of easiest sequences
samples of intermediate sequences
samples of challenging sequences
If you interested in our work, please cite:
@article{abdelpakey2019dp, title={DP-Siam: Dynamic Policy Siamese Network for Robust Object Tracking}, author={Abdelpakey, Mohamed H and Shehata, Mohamed S}, journal={IEEE Transactions on Image Processing}, volume={29}, pages={1479–1492}, year={2019}, publisher={IEEE} }